A satellite project of labs.iximiuz.com - an indie learning platform to master Linux, Containers, and Kubernetes the hands-on way 🚀
Ivan on Containers, Kubernetes, and Backend Development
Hello friends!
Ivan's here - this time not with a traditional monthly round-up but with a full-blown annual recap of the posts, streams, projects, and anything else that can help you master Kubernetes, containers, and the server-side craft. Let's begin!
Kubernetes
The year started with a series on Kubernetes API. The series is worth a read if you're developing Kubernetes controllers or any other forms of Kubernetes automation. A few months into this work, a job change shifted my focus back to Docker and containers, and the series never got to its culmination - the articles on client-go and controller-runtime are still missing. However, I tried to compensate for it with the client-go-examples project - a collection of mini-programs demoing various Kubernetes API use cases.
A somewhat related project I enjoyed working on at pretty much the same time was adding support for slimming Kubernetes workloads to DockerSlim. You can see it in action in this Rawkode Academy issue.
But my favorite Kubernetes project this year was, of course, the edu-tailored Kubernetes dashboard (working title "Kubeboard") that I've been developing rather secretly:
This dashboard will become the basis of my hands-on learning platform - you can read more about my vision in this post Learn-By-Doing Platform to Master Cloud Native Craft or even support my work by becoming a patron.
I also did two "standalone" Kubernetes write-ups. A practical one on ephemeral containers and the kubectl debug command and a more panoramic one (I'm proud of the story and the drawing there probably the most) - How Kubernetes Reinvented Virtual Machines:
Containers
This year I probably learned more about containers than in all the previous years combined. I'm not keeping up with sharing this knowledge on the blog - somehow, my posts are rather heavy and take a lot of time to produce. But not sharing these findings would be a crime, so I started the second newsletter called "Containers Tools, Tips, and Tricks." It's been three issues so far:
Thanks to Saim Safdar from Cloud Native Islamabad for nudging me (and providing the platform), I also tried a new format - online workshops ❤️🔥 Here you can see the recording of my containerd workshop, and my only regret is that I haven't done more of them:
GitHub projects was another form of sharing the container knowledge:
- Awesome Container Tinkering - an ever-growing list of tools to tinker with containers.
- cdebug - a swiss army knife of container debugging.
There were quite a few blog posts on containers this year, with What's Inside Of a Distroless Container Image: Taking a Deeper Look being the most successful one.
Miscellaneous
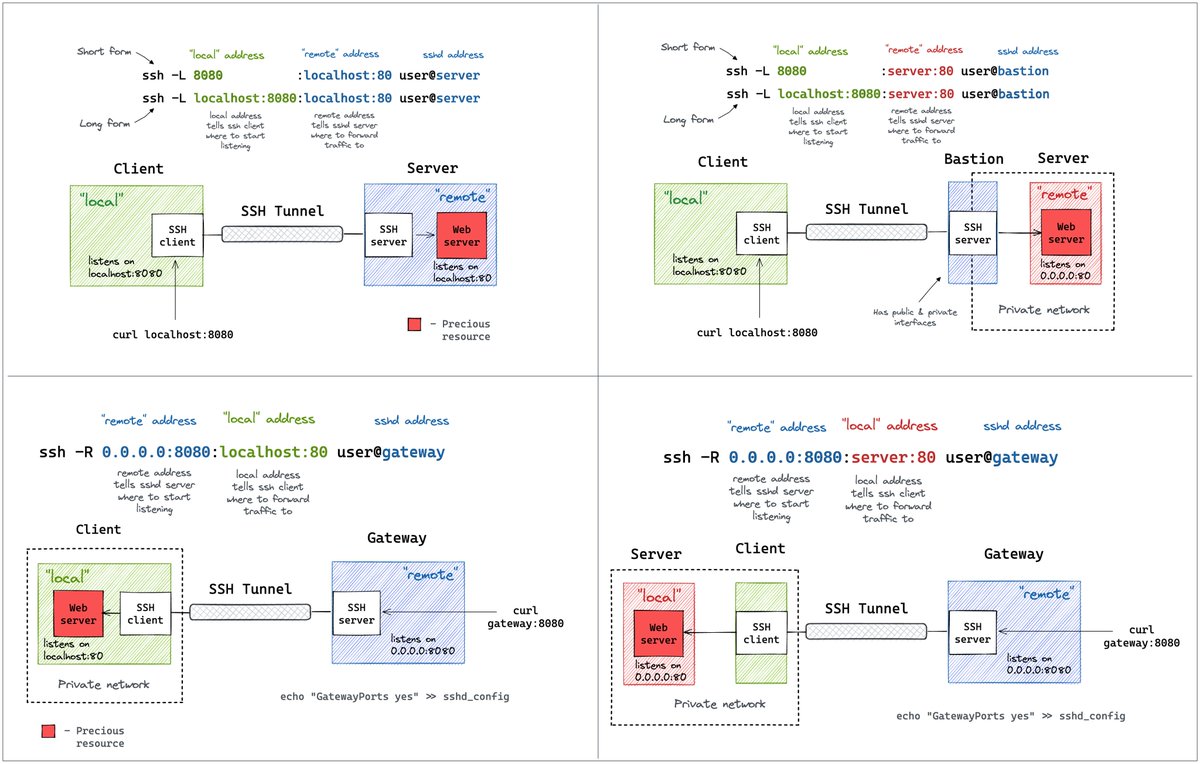
I also wrote a few posts on programming (1, 2) and a these SSH Tunnels diagrams came out pretty hot:
November 1st 2022
|

But probably the most surprising topic for me this year was writing about writing:
What I was reading (in December)
A Safer curl | bash by Dan Lorenc - building upon the idea of OCI Artifacts, Dan proposes to store binaries (and other artifact types too) in compatible container registries and then use the sigstore’s sget tool to fetch them. So, it becomes sget | bash instead of curl | bash, and since OCI registries are essentially content-addressable stores and sigstrore is all about signing immutable files, the new UX becomes a slightly friendlier alternative to curl. But you still need to pin the version (digest) and/or validate the signature.
Software Supply Chain Security: Broader Than SolarWinds and Log4J - a good overview of the most probable attack vectors and the corresponding mitigation means. The general theme is that there is no silver bullet yet - neither scanners, nor SBOMs, nor signing can fully protect you. But implementing more and more of these protective mechanisms on every level within our companies and the open source projects will make successful (and profitable) attacks harder and harder over time. So the industry should keep pushing for higher security standards.
Containers are chroot with a Marketing Budget - I love such types of articles. When someone goes the extra mile and not just rants about stuff but produces a hands-on write-up with plenty of supporting (visual) materials, it always deserves a shout-out. But from a purely technical standpoint, there were a few moments in this post that bugged me. In a nutshell, containers are portable execution environments. They contain our apps. And those portable execution environments are created by means of virtualization and filesystem images. There is no chroot in modern Linux containers, and some containers are true virtual machines (so even pivot_root maybe not be needed to implement them), but there is always one common theme behind all types of containers - they create isolated execution environments that feel the same way from the containerized app’s standpoint regardless if it’s launched on your personal laptop or in a remote Kubernetes cluster. Thus, focusing on chroot-ed processes and diminishing the role of namespaces (the main virtualization means of Linux containers) would make any attempt to explain the nature of containers rather misleading. IMO, of course. But go read that article anyway - it’s a good technical read! Just take it with a grain of salt.
Boosting Kubernetes container runtime observability with OpenTelemetry - when Kubernetes and Observability topics meet in one article, it’s usually about collecting telemetry produced by applications in a Kubernetes cluster. However, this post is different - it talks about OpenTelemetry instrumentation of the Kubernetes components themselves (such as the api-server, kubelet, CRI runtimes, etc). While it’s definitely a boon for cluster admins, I can see how this can also be applied for learning purposes. A thorough look at the kubectl -> api-server -> containerd -> runc trace can bring your understanding of how Kubernetes works to an absolutely different level.
Forensic container checkpointing in Kubernetes - some Kubernetes black magic sprinkled with a bit of necromancy. But CRIO is really cool. Now I’m thinking of adding a cdebug command to “clone” containers. And I’m not talking about committing, stopping, and then restarting a container from the committed state. I’m talking about much more complete snapshotting that includes not only the filesystem but also the runtime state (like a process tree).
What every SRE should know about GNU/Linux shell related internals: file descriptors, pipes, terminals, user sessions, process groups and daemons - a fantastic series on shell-related Linux internals (descriptors, pipes, terminals, user sessions, process groups, and daemons) from the author of SRE deep dive into Linux Page Cache.
Stack Overflow Bans ChatGPT - I find this ChatGPT thing rather alarming. Maybe I’m being pessimistic, but I can see many more negative applications of this tool than positive ones. Someone’s said, “LLMs confidently hallucinate information and present them as fact,” and I can’t agree more. Even positive applications of this (or similar) tech, like Copilot or fig, make me worry - it’s a known fallacy when developers copy/paste SO answers, but now you can just rely on “autocompletion” and more ill-understood but seemingly functional code will follow. However, to balance this take, here is a twitter thread with a bunch of seemingly useful applications of ChatGPT (with this one being probably the most interesting one). Here are some more good use cases. And here is my own try.
Scaling Mastodon is Impossible - a few thoughts on why Mastodon is not a good idea. While I’m not scared of technical scalability issues (I’ve been solving all sorts of them for quite a few years), the scalability of moderation and maintaining a homogeneous “platform culture” sounds much more challenging to me. And from the legal and security standpoints, Mastodon also seems to be rather messy at the moment.
Wrapping up
I'm looking forward to the next year. I'll keep writing and coding, and I'll try to give more talks and record a bunch of videos (my new year presents are a camera mount and decent lights). The goal is, as always - to help as many folks as just possible to master containers. If you find this goal worthy, you can always help me by spreading the word about my blog and this newsletter or by becoming a patron or corporate sponsor. Every attempt is highly appreciated!
Happy new year!
Ivan
Ivan on the Server Side
A satellite project of labs.iximiuz.com - an indie learning platform to master Linux, Containers, and Kubernetes the hands-on way 🚀